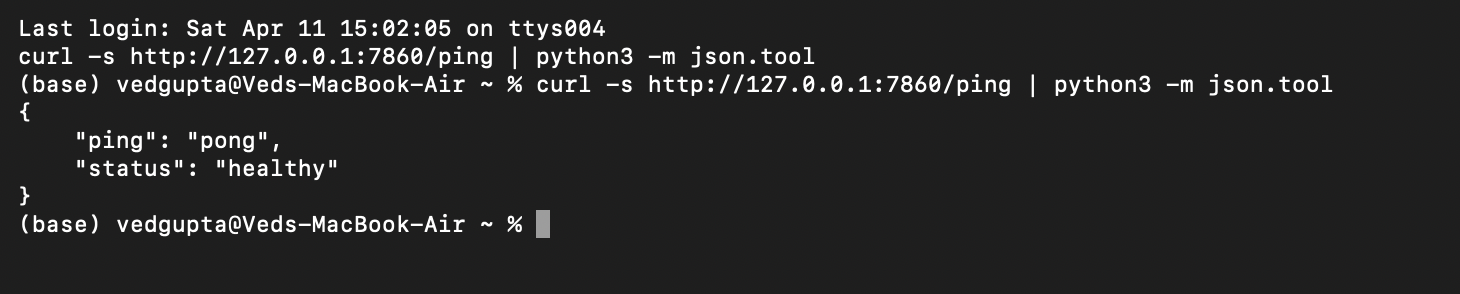
Whisper API is an open-source, self-hosted service for speech-to-text. It runs whisper.cpp under the hood and exposes a Deepgram-compatible surface (/v1/listen over REST and WebSocket), so full control of audio and data is maintained while reusing familiar integration patterns.
Key features
- Familiar API — Drop-in style compatibility with
/v1/listenfor uploads, JSON bodies (including transcribe-from-URL), and streaming. - Rich output — JSON with timings, plus SRT and VTT export options.
- Live streaming — Real-time transcription over WebSockets (16 kHz PCM).
- Advanced options — Custom vocabulary-style prompting, optional audio windowing (
start/duration) where supported. - Secure operations — API keys via a small CLI; URL ingest includes SSRF-oriented limits (size caps, host controls; redirects off by default).
- Documentation — Browse the live whisper.api docs (installation, auth, REST, WebSocket streaming, models, Docker, examples). The same site is built from the
docs/folder (Astro Starlight); run it locally with Bun if you are developing the docs.
Stack (high level)
FastAPI, SQLAlchemy (SQLite by default; PostgreSQL-friendly), async HTTP and WebSockets, and the whisper-cli binary from whisper.cpp. See the repo requirements.txt and setup_whisper.sh for the full setup path.
Quick start
Install dependencies, configure the environment, and pull/build whisper assets:
pip install -r requirements.txt
cp .env.example .env
chmod +x setup_whisper.sh
./setup_whisper.sh
Initialize storage and create an API key:
python -m app.cli init
python -m app.cli create --name "MyAdminKey"
Start the server (default dev port 7860):
uvicorn app.main:app --host 0.0.0.0 --port 7860
For local-only testing, Swagger can expose POST /v1/auth/test-token when ENABLE_TEST_TOKEN_ENDPOINT=true in .env. That flag defaults to off and should stay off in production.
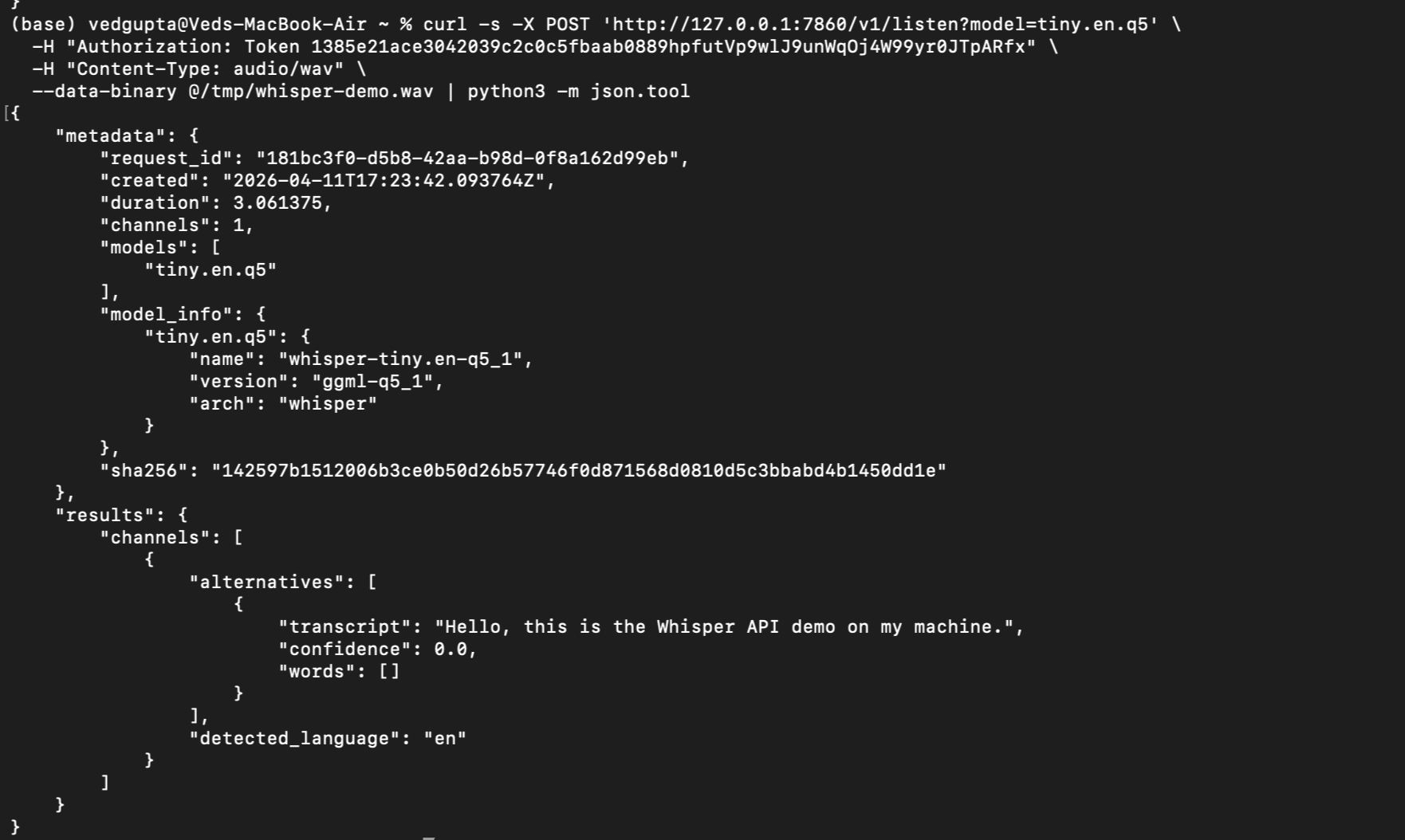
Example: transcribe a file
curl -X POST 'http://localhost:7860/v1/listen' \
-H "Authorization: Token <YOUR_KEY>" \
-H "Content-Type: audio/wav" \
--data-binary @audio.wav
Example: transcribe from URL
The server fetches the audio, with configurable download limits and safety defaults:
curl -X POST 'http://localhost:7860/v1/listen' \
-H "Authorization: Token <YOUR_KEY>" \
-H "Content-Type: application/json" \
-d '{"url": "https://example.com/audio.mp3"}'
Documentation
Online: https://whisper.vedgupta.in/docs/ — architecture overview, setup, authentication, REST and WebSocket API reference, models, Docker deployment, code examples, and contributing.
Local (from the repo):
cd docs && bun install && bun run dev